本文主要介绍两种树形结构用于求解回归问题:一种是回归树,叶节点用均值,误差用总方差衡量;另一种是模型树,叶节点为线性回归模型,误差用线性回归误差衡量。对样本集进行二分后,计算二分后误差有没有改善,如果没有,则停止二分;如果有改善,则继续进行二分。但是,如果节点过多,模型可能对数据过拟合,此时可以采用树剪枝处理,包括预剪枝和后剪枝。最后介绍MLiA一书中使用tkinter编写GUI交互调试树回归参数。
基本原理及算法
回归树
CART(Classification and Regression Trees)算法是树回归中十分著名的树构建算法。其思想和ID3算法类似,不同之处在于,数据划分采用二分方式,是否划分是根据总方差是否减少来决定,叶节点是数据集\(y\)的均值(数值型)。
1 | class treeNode(): |
1 | from numpy import * |
1 | testMat = mat(eye(4)) |
[[ 0. 1. 0. 0.]]
[[ 1. 0. 0. 0.]
[ 0. 0. 1. 0.]
[ 0. 0. 0. 1.]]1 | nonzero(testMat[:,1]<=0.5) |
(array([0, 2, 3]), array([0, 0, 0]))1 | def regLeaf(dataSet): |
1 | myDat = loadDataSet('ex00.txt') |
{'left': 1.0180967672413792,
'right': -0.044650285714285719,
'spInd': 0,
'spVal': 0.48813}1 | myDat1 = loadDataSet('ex2.txt') |
树剪枝
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。其基本策略包括预剪枝(prepruning)和后剪枝(postpruning),预剪枝是指在决策树生成过程中,对每个节点在划分前后进行估计,若果当前节点的划分不能带来泛化性能的提升,则停止划分,并将当前节点标记为叶节点;后剪枝则是先从训练集生成一颗完整的决策树,然后自底而上对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来泛化性能的提升,则将该子树替换为叶节点。
预剪枝
1 | createTree(myMat, ops=(0,1)) |
1 | myDat2 = loadDataSet('ex3.txt') |
1 | createTree(myMat2,ops=(10000,4)) |
{'left': 101.35815937735848,
'right': -2.6377193297872341,
'spInd': 0,
'spVal': 0.499171}后剪枝
1 | def isTree(obj): |
1 | myTree = createTree(myMat2, ops=(0, 1)) |
模型树
1 | def linearSolve(dataSet): |
1 | myMat2 = mat(loadDataSet('exp2.txt')) |
{'left': matrix([[ 1.69855694e-03],
[ 1.19647739e+01]]), 'right': matrix([[ 3.46877936],
[ 1.18521743]]), 'spInd': 0, 'spVal': 0.285477}后剪枝往往比预剪枝保留更多的分支,欠拟合风险更小,泛化性能往往优于预剪枝决策树。但是后剪枝是在生成完全决策树之后进行的,而且要自底而上对树中的所有非叶节点进行逐一考察,因此其训练开销比未剪枝和预剪枝决策树要大得多。
对比树回归与标准回归
1 | def regTreeEval(model, inDat): |
1 | # 回归树 |
0.964085231822214511 | # 模型树 |
0.97604121913806231 | # 标准的线性回归 |
0.94346842356747618图形交互
1 | from tkinter import * |
1 | from numpy import * |
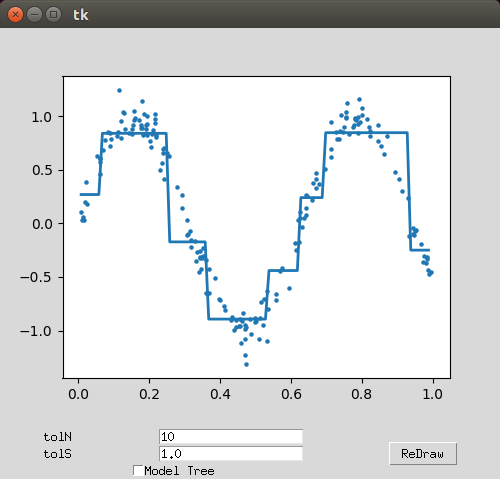
树回归
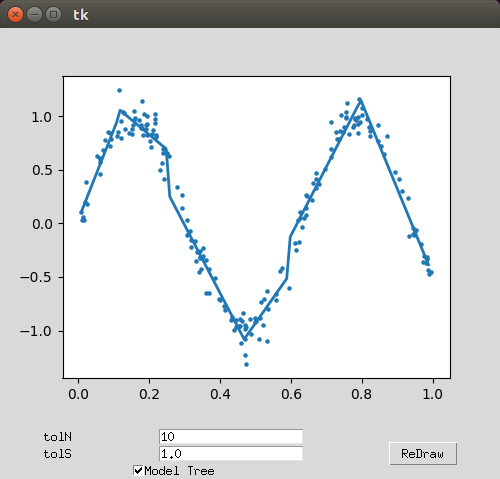
模型回归
结论及讨论
结论
树回归具有以下特点: > - 优点:可以对复杂和非线性数据进行建模 > - 缺点:结果不易理解
讨论
- 树回归和决策树中的叶节点上可以嵌入神经网络,如感知机树,甚至嵌入深度神经网络。
- 利用树结构进行增量学习,即在接受到新样本后对已学得的模型进行调整,而不用完全重新学习。其主要机制是通过调整分支路径上的划分属性次序对树进行部分重构,代表算法有ID4,ID5R等。
参考资料
- Peter Harrington, Machine learning in action, Manning Publications, 2012
- 周志华,机器学习,清华大学出版社, 2016

