深度神经网络是指多于一个隐藏层的神经网络。本文将详细介绍深度神经网络的基本原理及实现。涉及到模型的初始化、梯度的计算、激活函数的求导等内容。
符号 - 上标 \([l]\) 代表第 \(l\) 层的数值. - 例如: \(a^{[L]}\) 表示第 \(L\) 层激活函数的输出. \(W^{[L]}\) 和 \(b^{[L]}\) 表示第 \(L\) 层的参数. - 上标 \((i)\) 表示第 \(i\) 样本. - 例如: \(x^{(i)}\) 表示第 \(i\) 训练样本. - 下标 \(i\) 表示向量的第 \(i\) 个元素. - 例如: \(a^{[l]}_i\) 表示第\(l\)层第\(i\)个神经元的输出.
1 | import numpy as np |
网络结构
为建立神经网络,需要实现几个子函数,它们具体的功能包括:
- 初始化模型参数.
- 实现正传模块(下图紫色部分)Implement the forward propagation module (shown in purple in the figure below).
- 实现正传中的线性部分(得到 \(Z^{[l]}\)).
- 实现激活函数(relu/sigmoid).
- 结合前面两步形成一个新的正传函数[LINEAR->ACTIVATION].
- 将 [LINEAR->RELU] 正传函数重复 L-1 次 (从第 1 层到 L-1层) 并在最后一层添加 [LINEAR->SIGMOID] (第 \(L\)层). 那样就形成了 L_model_forward 函数.
- 计算损失函数.
- 实现反传模块 (下图红色部分).
- 计算反传中的线性部分.
- 实现激活函数的梯度(relu_backward/sigmoid_backward)
- 结合签名两步实现一个新的反传函数 [LINEAR->ACTIVATION].
- 将 [LINEAR->RELU] 反传 L-1 次并在最后一层加入[LINEAR->SIGMOID] 反传过程,那样形成了一个新的L_model_backward 函数
- 更新模型.
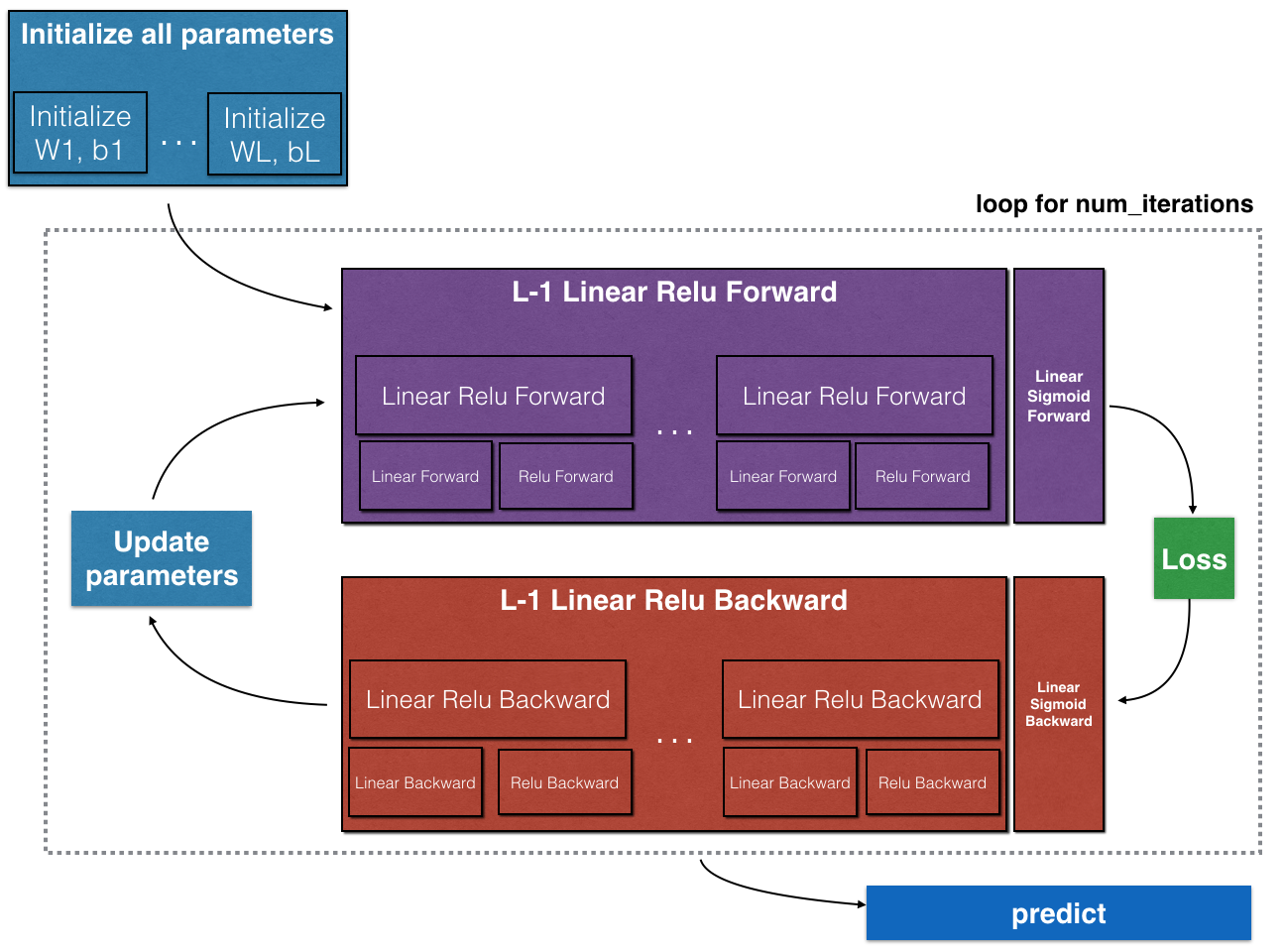
注意 在一个正传函数中,都有对应的反传函数,因此每一步都需要寄存一些值,用于计算梯度。
初始化
分别介绍两层和多层网络的参数初始化
两层网络
1 | # GRADED FUNCTION: initialize_parameters |
1 | parameters = initialize_parameters(2,2,1) |
W1 = [[ 0.01624345 -0.00611756]
[-0.00528172 -0.01072969]]
b1 = [[ 0.]
[ 0.]]
W2 = [[ 0.00865408 -0.02301539]]
b2 = [[ 0.]]\(L\)层网络
假定 \(n^{[l]}\) 是第 \(l\)层的神经元个数. 当输入 \(X\) 大小为 \((12288, 209)\) (其中 \(m=209\) 为样本数) ,则:
Python在计算 \(W X + b\)时, 使用了广播功能. 例如:
\[ W = \begin{bmatrix} j & k & l\\ m & n & o \\ p & q & r \end{bmatrix}\;\;\; X = \begin{bmatrix} a & b & c\\ d & e & f \\ g & h & i \end{bmatrix} \;\;\; b =\begin{bmatrix} s \\ t \\ u \end{bmatrix}\tag{2}\]
那么 \(WX + b\) 将为:
\[ WX + b = \begin{bmatrix} (ja + kd + lg) + s & (jb + ke + lh) + s & (jc + kf + li)+ s\\ (ma + nd + og) + t & (mb + ne + oh) + t & (mc + nf + oi) + t\\ (pa + qd + rg) + u & (pb + qe + rh) + u & (pc + qf + ri)+ u \end{bmatrix}\tag{3} \]
1 | # GRADED FUNCTION: initialize_parameters_deep |
1 | parameters = initialize_parameters_deep([5,4,3]) |
W1 = [[ 0.01788628 0.0043651 0.00096497 -0.01863493 -0.00277388]
[-0.00354759 -0.00082741 -0.00627001 -0.00043818 -0.00477218]
[-0.01313865 0.00884622 0.00881318 0.01709573 0.00050034]
[-0.00404677 -0.0054536 -0.01546477 0.00982367 -0.01101068]]
b1 = [[ 0.]
[ 0.]
[ 0.]
[ 0.]]
W2 = [[-0.01185047 -0.0020565 0.01486148 0.00236716]
[-0.01023785 -0.00712993 0.00625245 -0.00160513]
[-0.00768836 -0.00230031 0.00745056 0.01976111]]
b2 = [[ 0.]
[ 0.]
[ 0.]]正传模块
对所有样本向量化之后的正传模块实现如下公式:
\[Z^{[l]} = W^{[l]}A^{[l-1]} +b^{[l]}\tag{4}\]
其中 \(A^{[0]} = X\).
线性正传
1 | # GRADED FUNCTION: linear_forward |
1 | A, W, b = linear_forward_test_case() |
Z = [[ 3.26295337 -1.23429987]]线性正传+激活函数
实现正传 LINEAR->ACTIVATION .数学关系是: \(A^{[l]} = g(Z^{[l]}) = g(W^{[l]}A^{[l-1]} +b^{[l]})\) 其中激活函数 "g" 可以是 sigmoid() 或者 relu()
1 | # GRADED FUNCTION: linear_activation_forward |
1 | A_prev, W, b = linear_activation_forward_test_case() |
With sigmoid: A = [[ 0.96890023 0.11013289]]
With ReLU: A = [[ 3.43896131 0. ]]\(L\)层模型
为了实现 \(L\)层神经网络,可以复制前面的正传+ReLU激活函数 (linear_activation_forward + RELU) \(L-1\) 次, 然后接上 linear_activation_forward + SIGMOID.
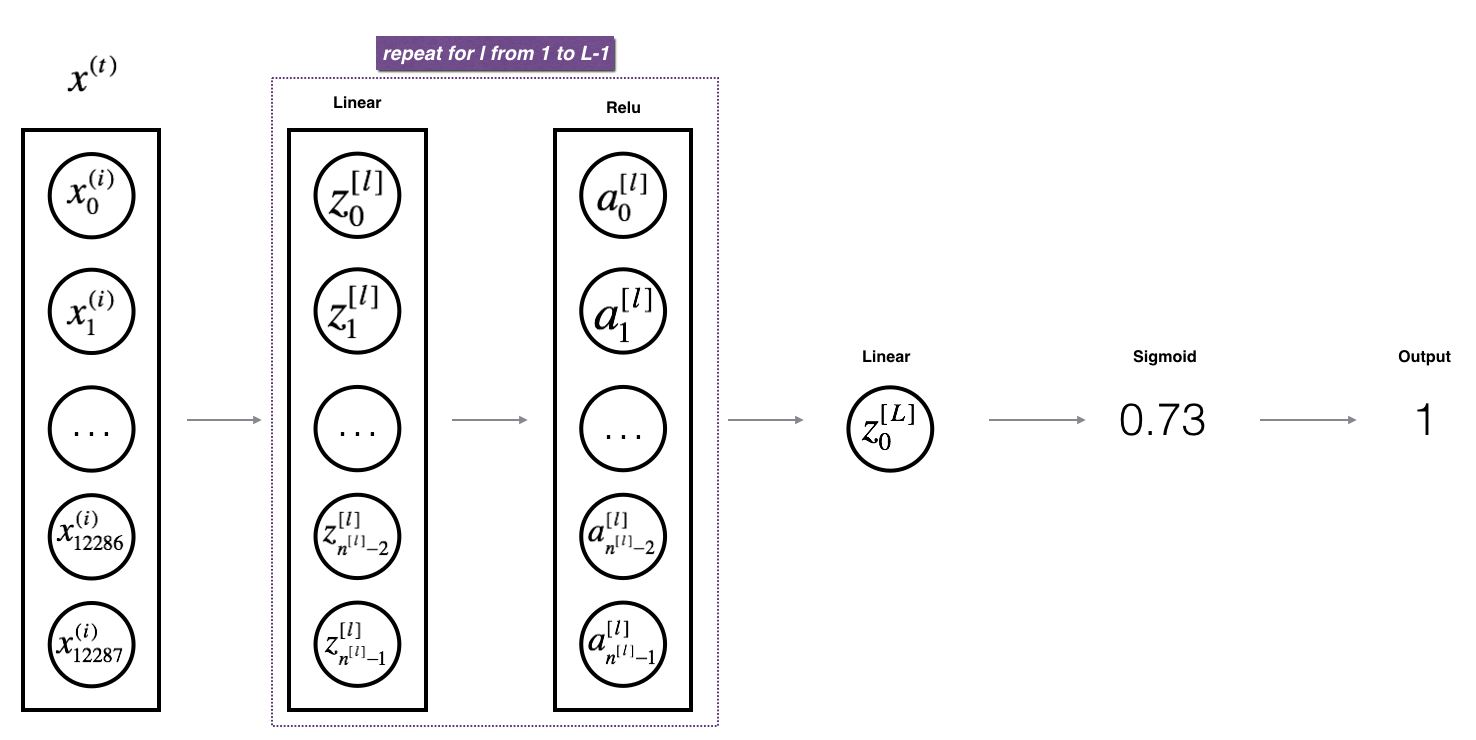
1 | # GRADED FUNCTION: L_model_forward |
1 | X, parameters = L_model_forward_test_case() |
AL = [[ 0.17007265 0.2524272 ]]
Length of caches list = 2代价函数
交叉熵代价函数 \(J\): \[-\frac{1}{m} \sum\limits_{i = 1}^{m} (y^{(i)}\log\left(a^{[L] (i)}\right) + (1-y^{(i)})\log\left(1- a^{[L](i)}\right)) \tag{7}\]
1 | # GRADED FUNCTION: compute_cost |
1 | Y, AL = compute_cost_test_case() |
cost = 0.414931599615反传模块
反传模块的作用是计算损失函数关于参数的梯度
提醒: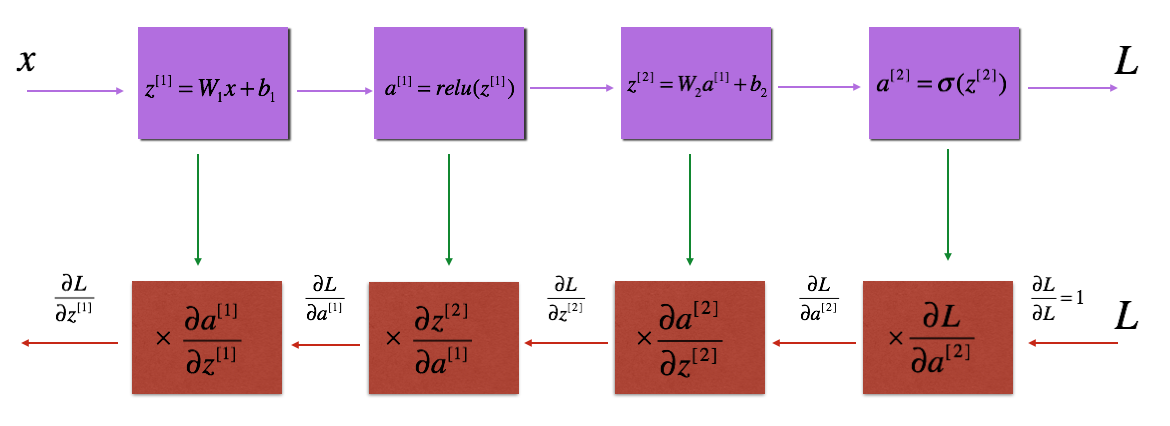
紫色方块表示正传过程, 红色模块表示反传过程.

