本文介绍一个提高深度神经网络性能的因素——初始化。不合理的初始化会降低收敛速度,甚至无法打破对称性,本文对比三种初始化方法:零初始化、大随机数初始化、He初始化。数值实验表明:合理的初始化会加快收敛速度。
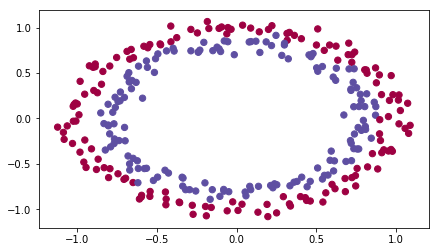
加载数据
1 | import numpy as np |
png
神经网络模型
本文使用已经实现好的3层神经网络,目的是测试不同的参数初始化方法对结果的影响:
- 零初始化
- 随机初始化:将模型参数初始化为很大的随机数
- He初始化:将模型参数初始化为较小的随机数,由He等人2015年提出
1 | def model(X, Y, learning_rate = 0.01, num_iterations = 15000, print_cost = True, initialization = "he"): |
零初始化
两种参数需要初始化:
- 权系数矩阵 \((W^{[1]}, W^{[2]}, W^{[3]}, ..., W^{[L-1]}, W^{[L]})\)
- 偏置向量 \((b^{[1]}, b^{[2]}, b^{[3]}, ..., b^{[L-1]}, b^{[L]})\)
1 | # GRADED FUNCTION: initialize_parameters_zeros |
1 | parameters = initialize_parameters_zeros([3,2,1]) |
W1 = [[ 0. 0. 0.]
[ 0. 0. 0.]]
b1 = [[ 0.]
[ 0.]]
W2 = [[ 0. 0.]]
b2 = [[ 0.]]1 | parameters = model(train_X, train_Y, initialization = "zeros") |
Cost after iteration 0: 0.6931471805599453
Cost after iteration 1000: 0.6931471805599453
Cost after iteration 2000: 0.6931471805599453
Cost after iteration 3000: 0.6931471805599453
Cost after iteration 4000: 0.6931471805599453
Cost after iteration 5000: 0.6931471805599453
Cost after iteration 6000: 0.6931471805599453
Cost after iteration 7000: 0.6931471805599453
Cost after iteration 8000: 0.6931471805599453
Cost after iteration 9000: 0.6931471805599453
Cost after iteration 10000: 0.6931471805599455
Cost after iteration 11000: 0.6931471805599453
Cost after iteration 12000: 0.6931471805599453
Cost after iteration 13000: 0.6931471805599453
Cost after iteration 14000: 0.6931471805599453
png
On the train set:
Accuracy: 0.5
On the test set:
Accuracy: 0.51 | print ("predictions_train = " + str(predictions_train)) |
predictions_train = [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]]
predictions_test = [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]1 | plt.title("Model with Zeros initialization") |
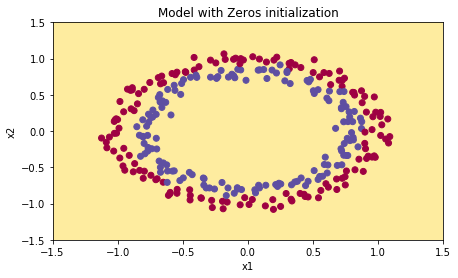
png
可以看出,结果表现很差,每次预测结果都是0.
原因:将权系数矩阵初始化为0,导致网络无法打破对称性,使得每层的每个神经元学习相同的东西,这就类似于训练一个每层神经元个数都是1的网络,因此它的性能不会优于普通的线性分类器(例如逻辑回归)。
随机初始化
为了打破对称性,可以对加权系数进行随机初始化,从而使得每个神经元学习不同的功能。这里使用随机初始化,但是是一些比较大的随机数。
1 | # GRADED FUNCTION: initialize_parameters_random |
1 | parameters = initialize_parameters_random([3, 2, 1]) |
W1 = [[ 17.88628473 4.36509851 0.96497468]
[-18.63492703 -2.77388203 -3.54758979]]
b1 = [[ 0.]
[ 0.]]
W2 = [[-0.82741481 -6.27000677]]
b2 = [[ 0.]]1 | parameters = model(train_X, train_Y, initialization = "random") |
/media/seisinv/Data/svn/ai/learn/dl_ng/init_utils.py:145: RuntimeWarning: divide by zero encountered in log
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
/media/seisinv/Data/svn/ai/learn/dl_ng/init_utils.py:145: RuntimeWarning: invalid value encountered in multiply
logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
Cost after iteration 0: inf
Cost after iteration 1000: 0.6242514034180014
Cost after iteration 2000: 0.5978936243041342
Cost after iteration 3000: 0.5636655312523394
Cost after iteration 4000: 0.5501079983602336
Cost after iteration 5000: 0.5443726908978377
Cost after iteration 6000: 0.5373784481765796
Cost after iteration 7000: 0.4712420718577742
Cost after iteration 8000: 0.39769537486465323
Cost after iteration 9000: 0.3934528103006004
Cost after iteration 10000: 0.39202183903799376
Cost after iteration 11000: 0.38915561357012357
Cost after iteration 12000: 0.38614000667817916
Cost after iteration 13000: 0.38497821466868465
Cost after iteration 14000: 0.3827524874203208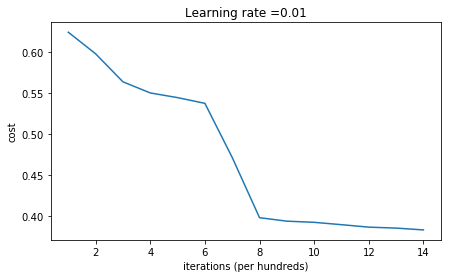
png
On the train set:
Accuracy: 0.83
On the test set:
Accuracy: 0.861 | plt.title("Model with large random initialization") |

png
小结:
- 代价函数开始很高。原因在于:使用很大的随机数,最后导致有些样本的激活函数的输出非常接近于0或者1,只要某一个样本分类错误,就会导致很高的代价函数,因为log(0)趋近无穷大。
- 初始化不理想会导致梯度消失/爆炸,降低收敛速度。
- 继续训练可以改善效果,但是使用大的随机数会降低收敛速度。
- 问题:应该使用多小的随机数?
He初始化方法
He初始化是以第一个作者He等人2015命名的。和Xavier初始化类似,它使用sqrt(2./layers_dims[l-1])加权随机数,而Xavier初始化使用sqrt(1./layers_dims[l-1])加权随机数。
1 | # GRADED FUNCTION: initialize_parameters_he |
1 | parameters = initialize_parameters_he([2, 4, 1]) |
W1 = [[ 1.78862847 0.43650985]
[ 0.09649747 -1.8634927 ]
[-0.2773882 -0.35475898]
[-0.08274148 -0.62700068]]
b1 = [[ 0.]
[ 0.]
[ 0.]
[ 0.]]
W2 = [[-0.03098412 -0.33744411 -0.92904268 0.62552248]]
b2 = [[ 0.]]1 | parameters = model(train_X, train_Y, initialization = "he") |
Cost after iteration 0: 0.8830537463419761
Cost after iteration 1000: 0.6879825919728063
Cost after iteration 2000: 0.6751286264523371
Cost after iteration 3000: 0.6526117768893807
Cost after iteration 4000: 0.6082958970572938
Cost after iteration 5000: 0.5304944491717495
Cost after iteration 6000: 0.4138645817071793
Cost after iteration 7000: 0.311780346484444
Cost after iteration 8000: 0.23696215330322562
Cost after iteration 9000: 0.1859728720920683
Cost after iteration 10000: 0.1501555628037181
Cost after iteration 11000: 0.12325079292273548
Cost after iteration 12000: 0.09917746546525937
Cost after iteration 13000: 0.0845705595402428
Cost after iteration 14000: 0.07357895962677369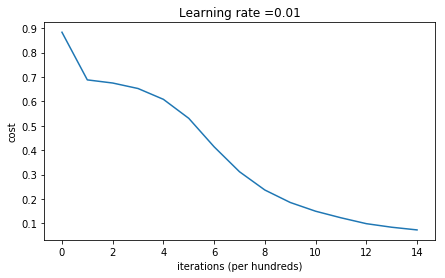
png
On the train set:
Accuracy: 0.993333333333
On the test set:
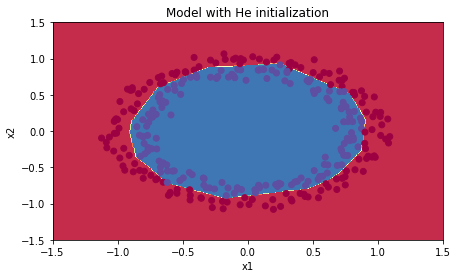
Accuracy: 0.961 | plt.title("Model with He initialization") |
png
小结:
- 使用He初始化方法可以在很少的迭代次数下对非线性可分的数据做好分类。
结论
- 不同的初始化方法,结果千差万别
- 随机初始化可以保证不同的神经元学习不同的内容,打破对称性
- 不能将权系数初始化成很大的随机数,否则会导致收敛速度很慢
- He初始化方法可以和sigmoid、ReLU激活函数一起工作。
参考资料
- 吴恩达,coursera深度学习课程

