线性回归是机器学习中最为重要的算法之一,简单高效,也是神经网络等非线性模型的基础。本文介绍线性回归、局部加权线性回归、L2/L1约束下回归(分别叫岭回归和Lasso回归),并引用MLiA一书中的程序和例子介绍算法细节和应用场景。
基本原理及算法
线性回归
原问题可描述为: \[ f(\mathbf{x}_i) = \mathbf{w}^T \mathbf{x}_i + b \] 使得 \[ f(\mathbf{x}_i) \approx y_i \] 将截距b吸收入向量\(\hat{\mathbf{w}} = (\mathbf{w};b)\),简化为\(\mathbf{w}\)。把数据集表示为\(m*(d+1)\)大小的矩阵,每行对应一个样本,一行中前\(d\)个元素对应于样本的第\(d\)个属性,最后一个元素恒为1,则原问题可以表述为求解以下反问题: \[ \mathbf{w}^* = argmin_{\mathbf{w}} (\mathbf{y} - \mathbf{X} \mathbf{w})^T ( \mathbf{y} - \mathbf{X} \mathbf{w}) \] 当\(\mathbf{X}^T\mathbf{X}\)为满秩矩阵时: \[ \mathbf{w}^* = (\mathbf{X}^T\mathbf{X})^{-1} \mathbf{X}^T \mathbf{y} \]
1 | from numpy import * |
1 | xArr, yArr = loadDataSet('ex0.txt') |
matrix([[ 3.00774324],
[ 1.69532264]])1 | # 绘制数据点及最佳拟合直线 |
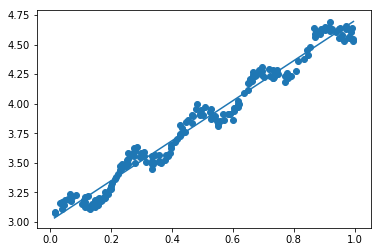
png
局部加权线性回归
线性回归很容易出现欠拟合现象,一种办法是局部加权线性回归(LWLR: Locally Weighted Linear Regression)。在该方法中,给待预测点附近的每个样点赋予一定的权重。 \[ \mathbf{w}^* = (\mathbf{X}^T \mathbf{W} \mathbf{X})^{-1} \mathbf{X}^T \mathbf{W} \mathbf{y} \] LWLR使用核方法的思想对附近点赋予更高的权重,核的类型可以自由选择,最常用的是高斯核,对应的公式为: \[ w(i) = exp \left ( -\frac{\|\mathbf{x}_{i} - \mathbf{x} \|^2}{2k^2} \right) \]
1 | def lwlr(testPoint, xArr, yArr, k=1.0): |
1 | # 测试一个点的预测结果和真实结果对比 |
[[ 3.12204471]] 3.1765131 | yHat = lwlrTest(xArr, xArr, yArr, 0.003) |
1 | # 绘制预测值和真实值对比图 |
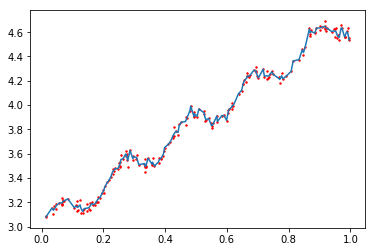
png
岭回归
当样本数量少于特征数量时,矩阵\(\mathbf{X}\)不满秩,为了解决这个问题,引入岭回归(ridge regression)。此时,回归系数的计算公式变为: \[ \mathbf{w}^* = (\mathbf{X}^T\mathbf{X} + \lambda \mathbf{I})^{-1} \mathbf{X}^T \mathbf{y} \]
1 | def ridgeRegres(xMat, yMat, lam=0.2): |
1 | abX, abY = loadDataSet('abalone.txt') |
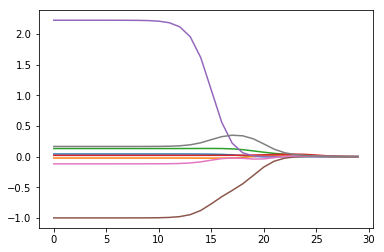
png
可以看出,权系数反应了哪些特征的影响最大,而随着\(\lambda\)的增大,权系数逐渐都缩小到0。一般在中间位置的效果最佳。
Lasso回归
实际上,岭回归和阻尼最小二乘法等价,阻尼最小二乘所增加的约束条件是: \[ \sum_{i=1}^{n} w_k^2 \leq \lambda \] 与岭回归类似,Lasso对回归系数增加如下约束: \[ \sum_{i=1}^{n} |w_k| \leq \lambda \] 该约束会使得回归系数分布更加稀疏。直接求解系数需要二次规划算法,比较费时,这里介绍一种贪心算法,叫做向前逐步回归。
1 | def regularize(xMat): |
1 | xArr, yArr = loadDataSet('abalone.txt') |
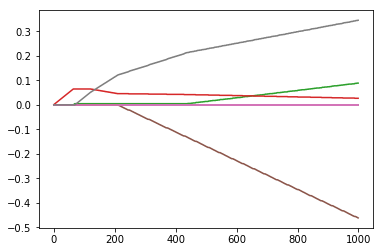
png
逐步线性回归的好处在于,可以快速的找到重要的特征,从而有可能及时停止对那些不重要特征的收集。
实例:预测乐高玩具价格
1 |
结论及讨论
结论
- 优点:结果易于理解,计算不复杂
- 缺点:对非线性拟合不好
讨论
- 对非线性回归问题,除局部加权线性回归外,还有一种简单有效的做法是引入高阶特征,然后用相同的程序进行线性回归。
- 线性回归是一种最重要、是最为常用的算法,同时也是神经网络方法的基础。神经网络通过加入层数来增加模型的泛化能力。
参考资料
- Peter Harrington, Machine learning in action, Manning Publications, 2012
- 周志华,机器学习,清华大学出版社, 2016

