本文介绍Tensorboard的基本用法,包括(1)可视化计算图,以便于分析网络结构;(2)实时分析各个计算节点的计算时间和内存消耗情况;(3)动态显示模型训练过程各个指标随迭代过程的变化过程;(4)降维显示输出层的分布情况,以加快错误案例分析过程。
计算图可视化
命名空间
1 | # 一个简单的写日志例子 |
上面的图可以看出,很多系统初始化过程也显示出来了,导致排列很乱。Tensorflow提供两个函数——tf.variable_scope和tf.name_scope来管理变量的命名空间,这样在默认情况下,只有顶层的命名空间中的节点才会显示出来。需要注意的是这两个函数在使用tf.get_variable时有些不同。
1 | tf.reset_default_graph() |
foo/a:0
bar/Variable:0
b:01 | # 改进显示方式 |
一个神经网络实例
1 | import os, time |
1 | # 神经网络结构相关的参数 |
1 | # 神经网络训练相关的参数 |
1 | def get_weight_variable(shape, regularizer): |
1 | from tensorflow.examples.tutorials.mnist import input_data |
1 | tf.reset_default_graph() |
Extracting /home/seisinv/data/mnist/train-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/train-labels-idx1-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-labels-idx1-ubyte.gz
After 1 training step(s), loss on training batch is 3.25722.
After 1001 training step(s), loss on training batch is 0.255171.
After 2001 training step(s), loss on training batch is 0.15627.
After 3001 training step(s), loss on training batch is 0.184929.
After 4001 training step(s), loss on training batch is 0.12473.
After 5001 training step(s), loss on training batch is 0.105338.
After 6001 training step(s), loss on training batch is 0.100877.
After 7001 training step(s), loss on training batch is 0.0858754.
After 8001 training step(s), loss on training batch is 0.0805109.
After 9001 training step(s), loss on training batch is 0.0716059.
After 10001 training step(s), loss on training batch is 0.0677174.
After 11001 training step(s), loss on training batch is 0.0638117.
After 12001 training step(s), loss on training batch is 0.0587943.
After 13001 training step(s), loss on training batch is 0.0571106.
After 14001 training step(s), loss on training batch is 0.0534435.
After 15001 training step(s), loss on training batch is 0.0495253.
After 16001 training step(s), loss on training batch is 0.0465476.
After 17001 training step(s), loss on training batch is 0.0477468.
After 18001 training step(s), loss on training batch is 0.0421561.
After 19001 training step(s), loss on training batch is 0.0456449.
After 20001 training step(s), loss on training batch is 0.0444757.
After 21001 training step(s), loss on training batch is 0.0374509.
After 22001 training step(s), loss on training batch is 0.0379014.
After 23001 training step(s), loss on training batch is 0.0426304.
After 24001 training step(s), loss on training batch is 0.0433503.
After 25001 training step(s), loss on training batch is 0.0399665.
After 26001 training step(s), loss on training batch is 0.0384408.
After 27001 training step(s), loss on training batch is 0.035355.
After 28001 training step(s), loss on training batch is 0.0338901.
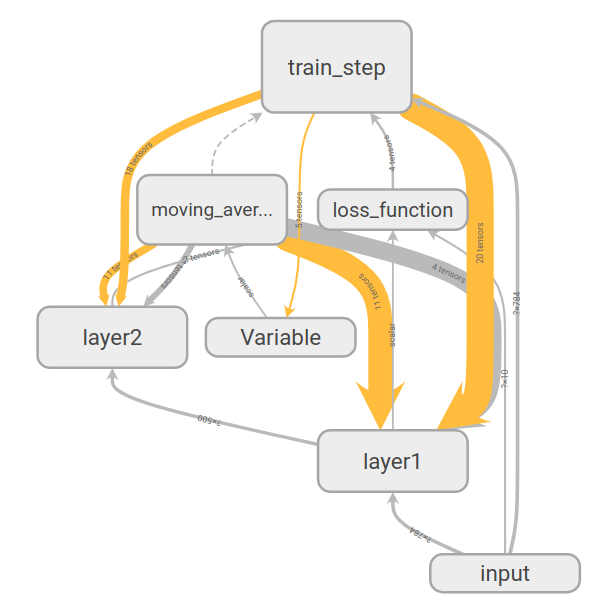
After 29001 training step(s), loss on training batch is 0.0374805.下图是上面代码运行之后使用tensorboard生成的计算图。带箭头的实线表示数据的传输方向,边上标注了张量的维度信息。但是当两个节点之间传输的张量多于1个时,只显示张量的个数。边的粗细代表两个节点之间传输的张量维度的总大小。虚线表示计算之间的依赖关系。
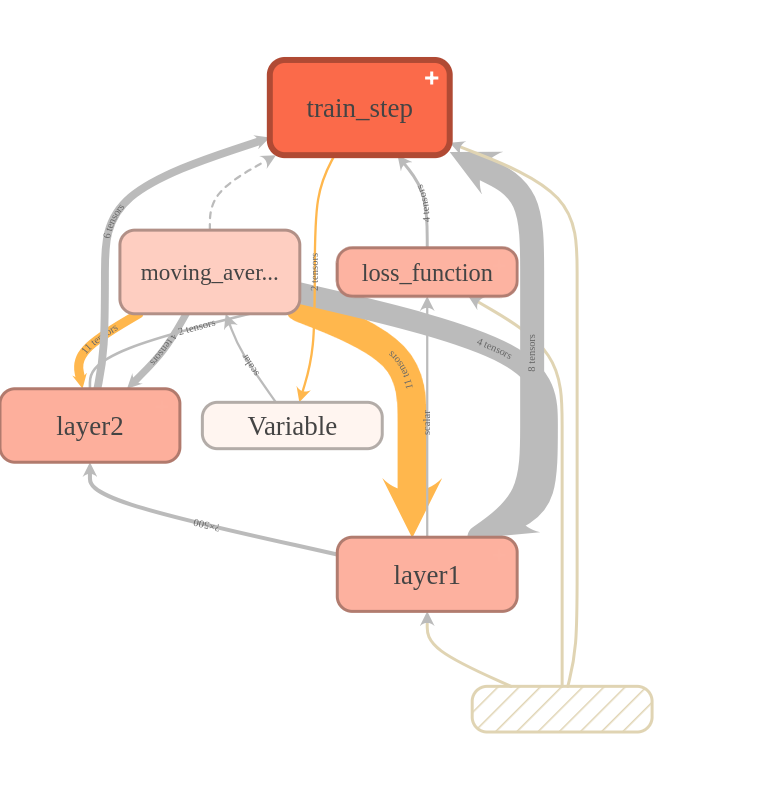
节点信息
Tensorboard除了可以显示计算图之外,还可以显示每个节点的运行时间和内存消耗情况,提供代码优化的重要信息。
1 | from tensorflow.examples.tutorials.mnist import input_data |
1 | tf.reset_default_graph() |
Extracting /home/seisinv/data/mnist/train-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/train-labels-idx1-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-labels-idx1-ubyte.gz
After 1 training step(s), loss on training batch is 2.96149.
After 1001 training step(s), loss on training batch is 0.237839.
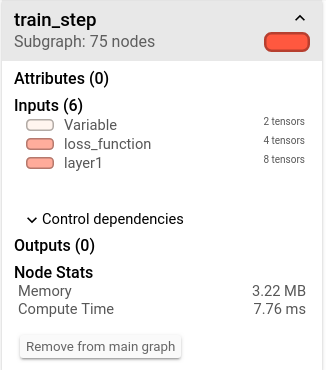
After 2001 training step(s), loss on training batch is 0.149025.下图显示了不同的计算节点时间和内存消耗的可视化效果图,颜色越深表示时间消耗越长。在性能调优时,一般会选择迭代轮数较大时的数据作为不同计算节点的时间/内存消耗标准,因为这样可以减少初始化对性能的影响。
监控指标可视化
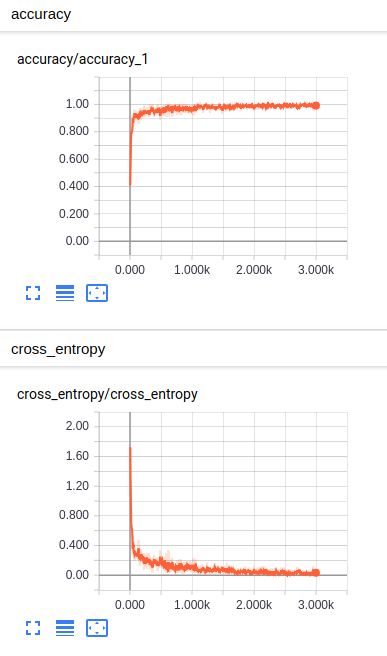
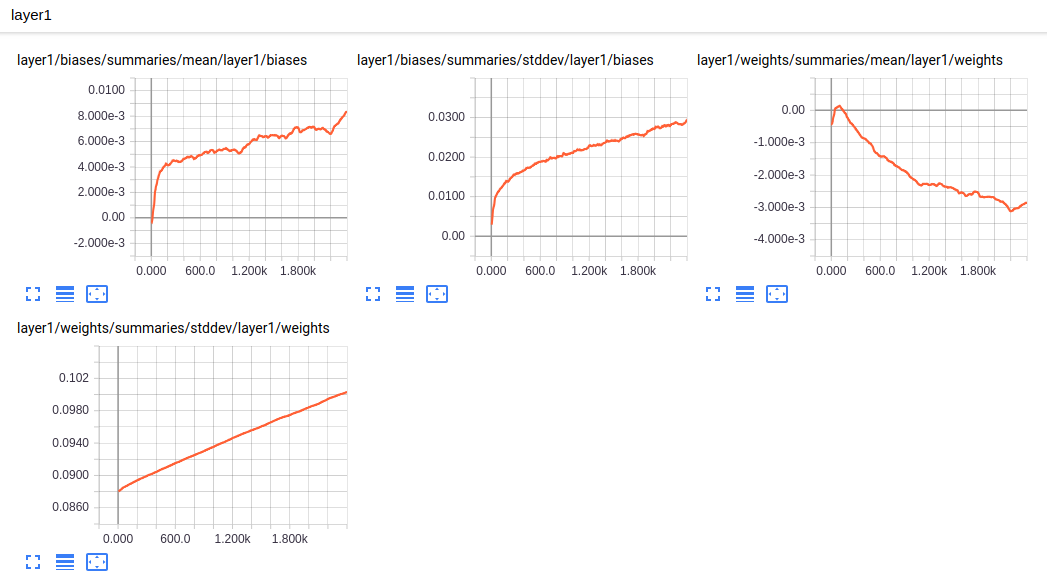
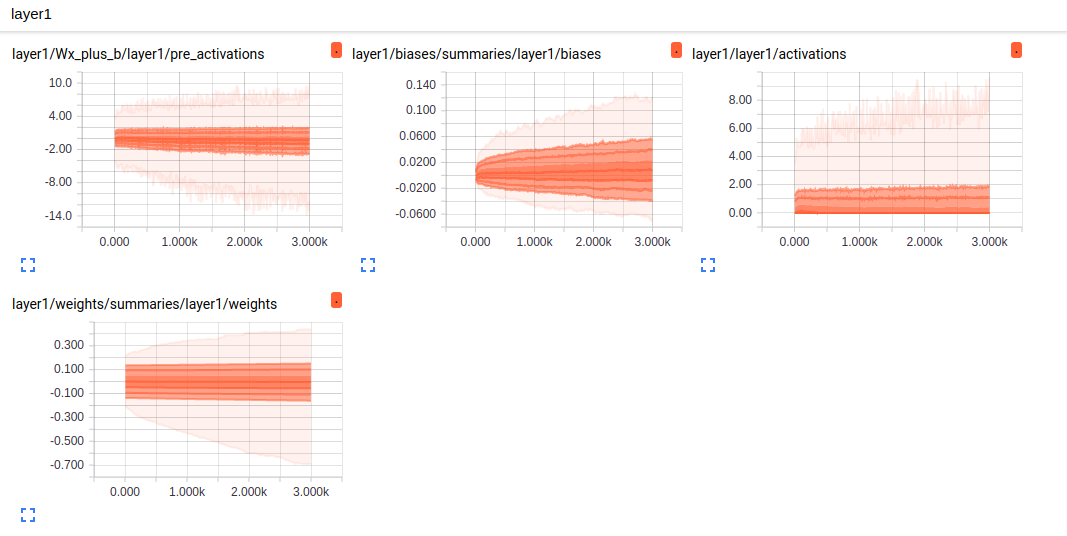
Tensorboard除了可以可视化计算图、查看各个节点的计算时间和内存消耗,还可以监控程序运行状态的指标。除了GRAPH外,TensorBoard还提供了SCALARS, IMAGES, AUDIO, DISTRIBUTIONS, HISTOGRAMS和TEXT六个界面来可视化其他的监控指标。
1 | SUMMARY_DIR = '/media/seisinv/Data/04_data/ai/test/log2' |
1 | tf.reset_default_graph() |
Extracting /home/seisinv/data/mnist/train-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/train-labels-idx1-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-labels-idx1-ubyte.gz下面是TensorBoard生成的日志文件
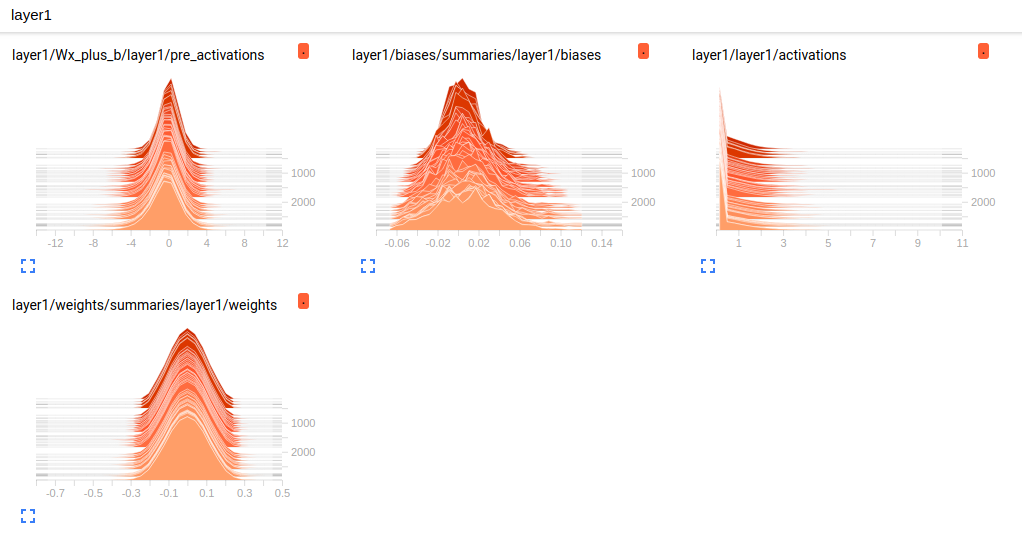
有以下日志生成函数:
- tf.summary.scalar,SCALAR, 显示标量监控数据随迭代进行的变化
- tf.summary.image,IMAGES, 可视化当前使用的训练/测试图片
- tf.summary.audio,AUDIO,使用的音频数据
- tf.summary.text,TEXT,使用的文本数据
- tf.summary.histogram,HISTOGRAMS, DISTRIBUTIONS,张量分布监控数据随迭代进行的变化
通过监控神经网络变量的取值变化、模型在训练batch上的损失函数大小以及学习率的变化情况,可以更加方便的掌握模型的训练情况。
高维向量可视化
TensorBoard提供了可视化高维向量的工具PROJECTOR,该工具需要用户准备一个sprite图像和一个tsv文件给出每张图片对应的标签信息。
以下代码给出了如何使用MNIST测试数据生成PROJECTOR所需要的文件。
1 | import matplotlib.pyplot as plt |
Extracting /home/seisinv/data/mnist/train-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/train-labels-idx1-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-labels-idx1-ubyte.gz
png
生成好辅助数据之后,以下代码展示如何使用TensorFlow生成PROJECTOR所需要的日志文件,以可视化MNIST测试数据在最后的输出层向量。
1 | from tensorflow.contrib.tensorboard.plugins import projector |
1 | BATCH_SIZE = 100 |
1 | INPUT_NODE = 784 |
1 | def train(mnist): |
1 | def visualisation(final_result): |
1 | def main(argv=None): |
Extracting /home/seisinv/data/mnist/train-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/train-labels-idx1-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-images-idx3-ubyte.gz
Extracting /home/seisinv/data/mnist/t10k-labels-idx1-ubyte.gz
After 0 training step(s), loss on training batch is 3.13751.
After 1000 training step(s), loss on training batch is 0.272537.
After 2000 training step(s), loss on training batch is 0.206967.
After 3000 training step(s), loss on training batch is 0.135616.
After 4000 training step(s), loss on training batch is 0.120108.
After 5000 training step(s), loss on training batch is 0.1051.
After 6000 training step(s), loss on training batch is 0.0955253.
After 7000 training step(s), loss on training batch is 0.0826855.
After 8000 training step(s), loss on training batch is 0.0760914.
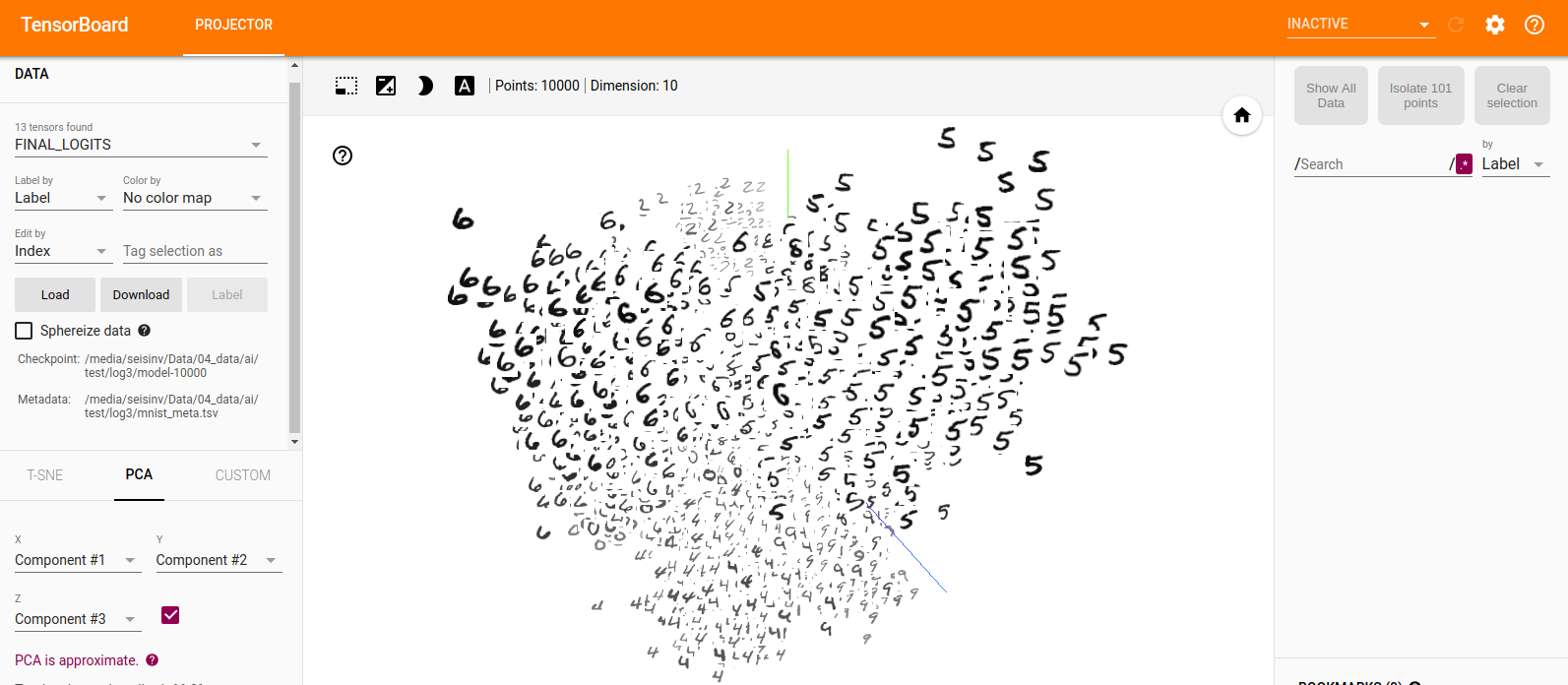
After 9000 training step(s), loss on training batch is 0.0718116.下图显示了使用PROJECTOR工具对输出向量经过PCA降维之后的显示结果,可以看出,经过10000次迭代之后,不同类别的图片比较好的区分开来了。在右边可以搜索特定的标签,这样可以快速的找到类别中比较难分的图片,加快错误案例的分析过程。
当然,除了PCA以外,tensorflow也支持t-SNE降维方法。

结论
本文介绍了TensorBoard这种检测TensorFlow运行状态的交互工具,通过输出日志文件,可以实现的功能包括:
- 了解计算图的结构
- 分析每个计算节点的运行时间及内存消耗情况,以提供优化程序的重要参考信息
- 可视化模型训练过程的各种指标,直观地了解训练情况以提供优化模型的重要信息
- 降维分析输出层的分布情况,快速找到难分的图片,加快错误案例分析过程
参考资料
- 郑泽宇、梁博文和顾思宇,Tensorflow: 实战Google深度学习框架(第二版)

